位置:首页 > 安全分类 > WEB安全
基于Hadoop生态圈的数据分析平台设计
自贵州省实施大数据战略以来,全省社会经济高速发展,通过支付系统贵阳城市处理中心处理的跨行资金交易呈快速增长态势,如何从海量真实交易数据中提取和分析有效信息,对支付系统贵阳城市处理中心提升工作效率、为贵州省人民银行系统及地方政府提供管理决策依据等方面都具有重要意义。
支付系统贵阳城市处理中心现有数据统计分析系统仅提供了跨行资金交易数据的基础查询和初步统计功能,对于全省全年全系统或全省半年全系统或某地区特殊固定时段全系统的数据则需要进行二次人工统计,不仅耗时且容易出错,而对于领导关心的行业资金流入流出、企业资金流入流出、不同时段下资金流动监测预警、各地区经济发展动向等情况则完全无法实现。在全行要求过“紧日子”的背景条件下,为有效解决当前工作存在的问题,高效快速完成对海量跨行交易数据的统计查询,支撑更具深度的数据挖掘分析,实现直观的数据可视化展示,建设一套低成本、高效率的央行支付系统区域数据分析平台迫在眉睫。
本文旨在通过利用支付系统贵阳城市处理中心已有的PC机及网络设备作为硬件基础,结合Hadoop、Hive、HBase、Spark等开源产品,对贵州省央行支付系统数据分析平台进行实践分析。该平台设计方案与原数据统计分析系统基于单机处理的设计方案对比情况如表1所示。
表 1 原数据统计分析系统与基于Hadoop的
贵州省央行支付系统数据分析平台对比
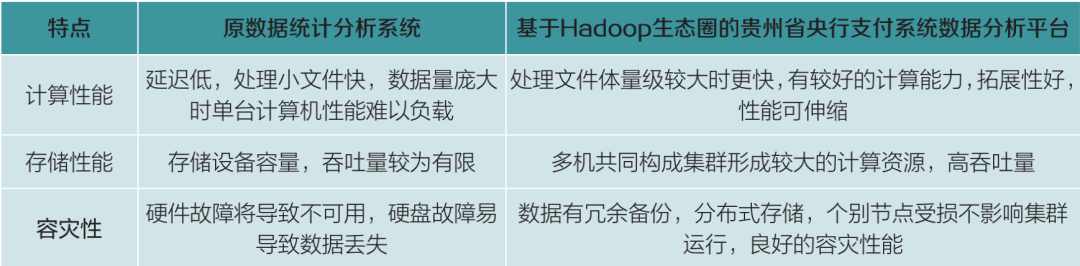
功能分析
贵州省央行支付系统数据分析平台应实现对全省跨行资金交易的数据处理、查询统计、风险预警、多维分析、报告输出和系统管理等功能,其中,数据处理包括数据采集、数据清洗、数据加密等;查询统计即对原数据统计分析系统的数据统计、业务量查询、流量流向统计、精确交易查询等功能进行完善和优化;风险预警即对交易金额、交易笔数、可疑交易等进行预警;多维分析即实现基于业务需求拖拉拽可视化组件进行自助分析,可灵活配置相关指标字段、过滤条件、结果展示等选项,实现对贵州省内各行业资金流动情况、各地区经济发展动向等内容的动态分析;报告输出即根据相关报告模板,结合预设指标参数、算法等,自动填充对应内容,生成图文表并茂的分析报告;系统管理则实现用户管理、资源管理、权限管理、日志管理等系统后台管理功能。
平台设计
1.平台架构设计。平台架构设计除数据源外,平台按照数据采集层、存储层、应用层、业务层、数据展示层共5个模块进行划分。数据采集层主要负责对原始数据的采集和清洗,经过预处理后的数据流向存储层;存储层负责根据业务功能需求和性能考量,提供相匹配的数据存储方式,为业务层和应用层服务;业务层主要负责实现业务处理相关事务,封装业务层面上的算法逻辑,供应用层引入调用;应用层负责与用户交互,根据用户指令对接业务层处理逻辑,调度计算任务,管理各项资源以及调整系统设定;数据展示层负责将处理完毕的数据结果以图表、表格、导出文件等形式反馈至用户。
2.平台搭建。集群复用支付系统贵阳城市处理中心现有9台运维终端,平均每个计算节点分配硬件资源为12核心CPU、28G内存、1TBSSD硬盘,集群部署于支付系统专网运维区,便于系统自动采集更新属地数据,用户通过其他运维终端对集群进行管理。
各计算节点基于Linux部署Hadoop-3.3.0集群,其中1个Master节点、8个Worker节点,通过Zookeeper实现高可用,在Hadoop NameNode上部署Hive数据仓库供数据管理,集群上搭建HBase供快速响应查询,部署Spark提供流式数据处理能力,并弥补Hadoop在执行MR任务耗时较长的短板,集成Superset作为BI工具对数据进行抽取整合,提供展示图表等。
3.原始数据。该平台的数据来源主要分为属地数据和外部数据,其中,属地数据为CSV格式,包含所有流入流出贵州省大小额支付系统、网银支付系统和外币支付系统的支付交易数据,平均每日约80万行1GB的数据量,涵盖每笔交易的交易时间、业务类型、发起行行号、接收行行号、收款人账户及姓名、付款人账户及姓名、交易金额、轧差情况、清算情况、业务处理状态、回执信息等近38个字段。辅助数据则主要来源于公开数据及相关合作渠道,目前可使用的有银行行名行号数据、地理区域结构数据、企业注册数据、行业分类数据、企业信用数据、基金股票统计数据等。
4.数据采集层。为实现每日获取的属地数据为最新数据,可通过Crontab调用Shell脚本实现,设定每间隔6小时检测一次最新数据并完成下载,使用Python脚本对下载后数据进行安全性及完整性检查,由于CSV格式属于结构化数据,入库前的数据清洗工作主要针对个人账号姓名等敏感信息进行脱敏处理。原始属地数据则加密压缩后存放于HDFS中,以备特殊情况下的调取使用。由于部分数据挖掘功能需要引入外部数据,如各行业资金流动分析功能依赖于企业工商等信息数据,流量流向则依赖于行号地址映射关系数据,此类数据由于网络隔离的原因无法实时拉取,由人工定期导入更新,在经过清洗消歧后,属地数据与外部数据关联聚合后流向存储层。
5.存储层。原始数据在经过加密压缩后通过Hadoop的HDFS文件系统存储,设置副本冗余策略为3个。部署Hive作为数据仓库存放CSV格式数据,便于后续通过HQL语句转化MR任务对数据进行抽取,创建满足不同业务需要的数据集。部署HBase存放需要快速响应的数据,存放时考虑查询可行性、性能等问题,分别针对不同查询场景设计RowKey和列簇,形成多个表格,确保数据查询简单可行,避免查询扫描时负载过度集中在个别RegionServer带来性能I/O瓶颈、数据过度分散等问题,进而导致连续数据查询效率低下等问题。
6.应用层。应用层前端Web界面采用Layui编写,供业务操作人员使用与后端通讯,后端部分主要通过Flask框架开发,集成HDFS、PyHive、HappyBase、PySpark等Python库以实现常用功能,搭配调用LinuxShell自动化脚本实现对宿主主机监测以及系统级管理。预留自定义功能接口,以便Shell脚本、Python脚本、Mapreduce Jar包等上传,供系统调用实现特定功能。
7.业务层。业务层作为核心组件,需要开发人员根据特定需求对业务系统和数据有较深的理解,面对各式各样的应用场景,采用的算法模型可能各有不同,所以业务层应集成常见算法,且对各算法的参数阈值应设置为可调整。以ID3决策树算法为例,可应用于判断金融机构在不同地段部署网点的合理性,通过支付系统跨行交易数据结合行号地址映射关系数据能够提取出金额、频率、城区中心化程度等信息,再通过本地调研选取公认分配合理的网点作为训练样本,发现累计交易金额大、频度高、所在位置等属性特征,建立模型,可以找出相对设置不够合理的网点,供金融机构参考判断是否需要调整策略、加以优化。
8.数据展示层。平台对数据分析完毕后,采用基于WebUI的直观图形图表将处理后的数据进行展示。该部分功能主要选用开源免费的BI工具Superset实现,该工具通过连接Hive数据库读取数据仓库中的交易数据,连接Mysql数据库读取交易统计数据、外部导入的企业工商、行号地址映射关系数据,而Superset原生集成Echarts图表库,可方便灵活根据业务需求创建数据集、可视化图表。
9.数据安全性保护。该平台所部署的集群位于支付系统贵阳城市处理中心内部专有网段,与外部网络物理隔绝,可有效防止外部网络攻击。数据采集后在进行数据清洗时,要根据相关管理制度对数据中部分字段进行脱敏屏蔽,对于敏感隐私信息进行Hash处理,实现如收付款人姓名等隐私信息仅可在得到准确信息的情况下才可以展示,普通操作人员无法直接浏览。而原始数据均经过加密压缩后再进行存储,在确保数据分析准确性的同时又能保证敏感信息不被泄露。
下一步工作方向
基于Hadoop生态圈的贵州省央行支付系统数据分析平台设计,在有限成本预算的情况下,能够有效提高分析速度,充分利用好属地数据,解决当前工作中的遇到的一些难题,相较传统单机处理分析的技术实现方法,更适应当今复杂多变的应用需求,高可用性和数据冗余存储的设计更是提高了整个系统的可用性,但与之相对的则是需要额外增加对整个集群的维护管理,对运维工作带来一定的负担。
下一步工作方向:一是结合对数据关联关系的挖掘需求,引入更多算法,探究在不同金融研究领域下的更多应用;二是使用Docker技术建立私有镜像,提高部署效率,防止节点老化损坏后,给运维工作恢复时带来的繁重配置工作,降低集群维护难度,提高灾后重建能力。
上一篇: 杀伤链已过时
下一篇:浅析内网渗透中协议基础与常见手法
栏目导航
推荐资讯
- 解码API安全-挑战、威胁和最佳实践...
 一、序言API为当今大多数数字体验提供了动力,API安全性仍然是大多数CXO最关心的问题。尽管数字化转型不断推...
一、序言API为当今大多数数字体验提供了动力,API安全性仍然是大多数CXO最关心的问题。尽管数字化转型不断推... - 3大Web安全漏洞防御详解:XSS、CSRF、以及SQL注入解决方案...
 随着互联网的普及,网络安全变得越来越重要。Java等程序员需要掌握基本的web安全知识,防患于未然,下面列举一些...
随着互联网的普及,网络安全变得越来越重要。Java等程序员需要掌握基本的web安全知识,防患于未然,下面列举一些...
站长推荐
- 29岁转行转行网络安全是否值得呢?...
 29岁转行网络安全,这个选择合适吗?在当今数字化时代,网络安全已成为一个越来越受到人们关注的领域。越来越多的...
29岁转行网络安全,这个选择合适吗?在当今数字化时代,网络安全已成为一个越来越受到人们关注的领域。越来越多的... - 注意!你的网站可能已被DNS劫持:如何见招拆招?...
 想象一下,你正准备在网上进行一次重要的银行转账,你打开了看似官方的网站,输入了你的账号和密码。然而,你并不知...
想象一下,你正准备在网上进行一次重要的银行转账,你打开了看似官方的网站,输入了你的账号和密码。然而,你并不知... - 2024年转行做网络安全工程师还来得及吗?薪资怎么样呢...
 2022年以来,我国网络安全行业的市场规模持续增长,根据市场调研在线网发布的2023-2029年中国网络安全集成行业...
2022年以来,我国网络安全行业的市场规模持续增长,根据市场调研在线网发布的2023-2029年中国网络安全集成行业... - 2024年网络安全工程师的发展前景如何?红利还有吗?...
 2021年7月12日工信部发布的《网络安全产业高质量发展三年行动计划(2021-2023年)》,文件中提出,2023年网络安全...
2021年7月12日工信部发布的《网络安全产业高质量发展三年行动计划(2021-2023年)》,文件中提出,2023年网络安全... - 学网络安全需要报名参加培训吗?如何选择培训机构?...
 在云计算、大数据、工业互联网、物联网等行业快速发展所带来的下游客户的安全需求增长下,网络安全行业迎来了...
在云计算、大数据、工业互联网、物联网等行业快速发展所带来的下游客户的安全需求增长下,网络安全行业迎来了... - 网络安全行业人才缺口大吗?薪资怎么样?有哪些新兴岗位呢...
 网络安全行业是当下非常热门的行业之一,其不仅具有较高的关注度,也是IT行业内热议的话题,尤其是在当下,不少人都...
网络安全行业是当下非常热门的行业之一,其不仅具有较高的关注度,也是IT行业内热议的话题,尤其是在当下,不少人都...
官方微信
